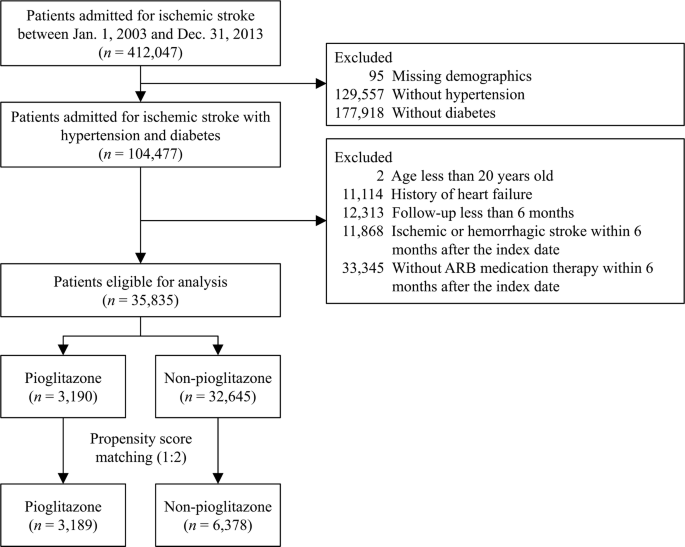
Propensity Score Matching Table

Propensity Score Matching Assessment Download Table

Propensity Score Matching Characteristics Download Table

Propensity Score Matching Download Table

Propensity Score Matching And Covariate Balance Download Table

Propensity Score Matching Showing Standardized Differences 0 1 Download Table

Characteristics Of Patients Before After Propensity Score Matching By Download Table

The teffects psmatch command has one very important.
Propensity score matching table. Based on descriptives it looks like this data matches columns 1 and 4 in table 3 3 2. A quick example of using psmatch2 to implement propensity score matching in stata. In general the propensity score methods give similar results to the logistic regression model. However stata 13 introduced a new teffects command for estimating treatments effects in a variety of ways including propensity score matching.
Specifically the generalized propensity score cumulative distribution function gps cdf method is introduced. Psm attempts to reduce the bias due to confounding variables that could be found in an estimate of the treatment effect. This is well known finding from previous empirical and simulation studies. Comparable but patients with the same propensity score are comparable.
For many years the standard tool for propensity score matching in stata has been the psmatch2 command written by edwin leuven and barbara sianesi. Note the slight discrepancy in statistical significance for the matching method where the 95 confidence interval for the odds ratio was calculated by the standard approximation and may be too wide. In the statistical analysis of observational data propensity score matching psm is a statistical matching technique that attempts to estimate the effect of a treatment policy or other intervention by accounting for the covariates that predict receiving the treatment. 1 select covariates 2 assess table 1 balance in risk factors before propensity score implementation 3 estimate and implement the propensity score in the study cohort 4 reassess table 1 balance in risk factors after.
A one parameter power function fits the cdf of the gps vector and a resulting scalar balancing score is used for matching and or stratification. Propensity score matching in stata using teffects. We propose the following 5 step checklist to guide the use and evaluation of propensity score methods.

Full Text Review Propensity Score Methods With Application To The Help Clinic C Oams

Table 5 From Multicentre Propensity Score Matched Analysis Of Laparoscopic Versus Open Surgery For T4 Rectal Cancer Semantic Scholar

Pdf A Tutorial And Case Study In Propensity Score Analysis An Application To Estimating The Effect Of In Hospital Smoking Cessation Counseling On Mortality

Full Text An Evaluation Of Exact Matching And Propensity Score Methods As Applie Por

Full Text Get The Most From Your Data A Propensity Score Model Comparison On Re Ijgm

Pdf Propensity Score Matching A Conceptual Review For Radiology Researchers

View Image

Standardized Differences Before And After Propensity Score Matching Download Scientific Diagram
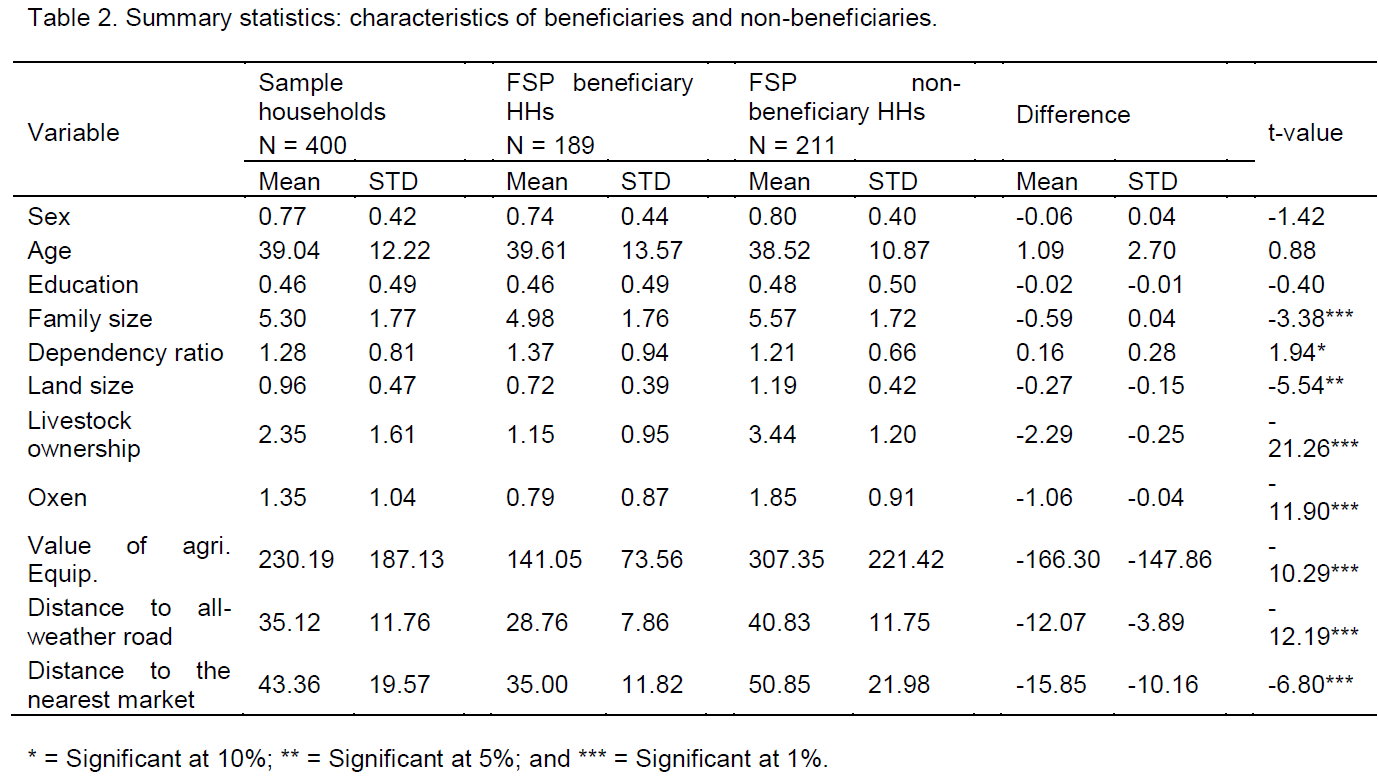
Journal Of Development And Agricultural Economics Estimating The Impact Of A Food Security Program By Propensity Score Matching

Pdf The Use Of Propensity Score Matching In The Evaluation Of Active Labour Market Policies
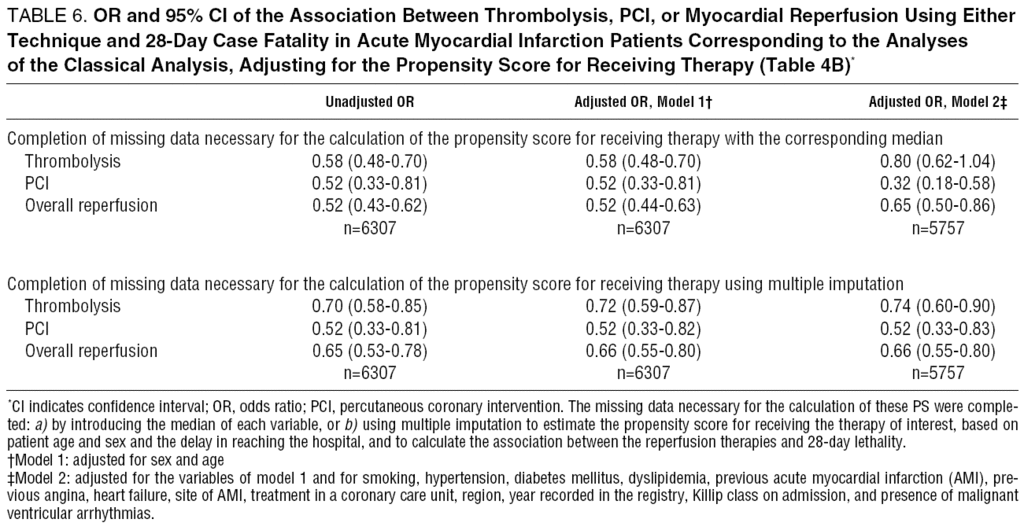
Analysis With The Propensity Score Of The Association Between Likelihood Of Treatment And Event Of Interest In Observational Studies An Example With Myocardial Reperfusion Revista Espanola De Cardiologia English Edition
Pdf Reducing Bias In A Propensity Score Matched Pair Sample Using Greedy Matching Techniques Semantic Scholar

Propensity Score Matching In Stata Youtube

Chapter 2 Overview Of Propensity Score Methods Semantic Scholar
Https Support Sas Com Resources Papers Proceedings17 Sas0332 2017 Pdf
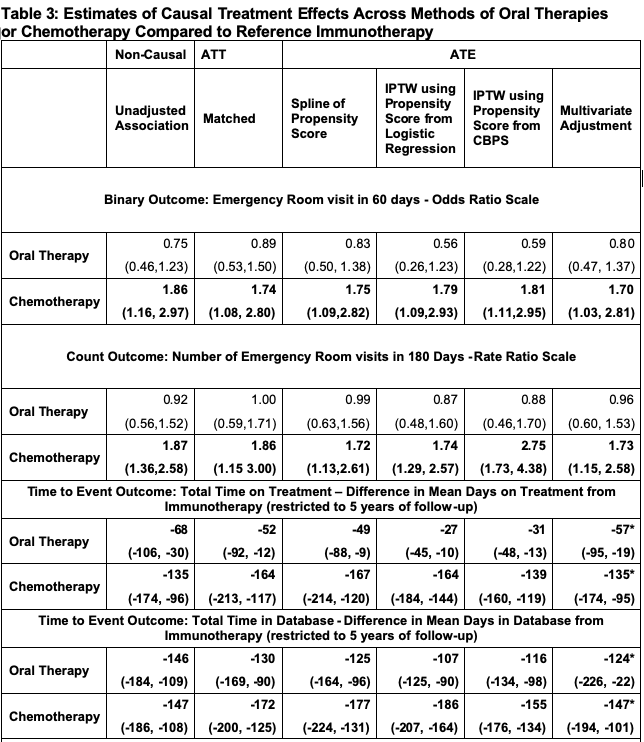
Veridical Causal Inference Propensity Score Tutorial With R Code

Pdf Propensity Score Matching With Limited Overlap

Pdf Juvenile Transfer And Recidivism A Propensity Score Matching Approach

Pdf Assessing Bias In The Estimation Of Causal Effects Rosenbaum Bounds On Matching Estimators And Instrumental Variables Estimation With Imperfect Instruments

Pdf A Propensity Score Approach In The Impact Evaluation On Scientific Production In Brazilian Biodiversity Research The Biota Program

Early Outcomes Of Robot Assisted Versus Thoracoscopic Assisted Ivor Lewis Esophagectomy For Esophageal Cancer A Propensity Score Matched Study Semantic Scholar

Propensity Score Matching In R

Comparison Of Covariate Balance Between Nsaids And Acetaminophen Before Download Table

Pdf Weight Trimming And Propensity Score Weighting

Flow Chart Of Patient Selection And Propensity Score Matching Analysis Download Scientific Diagram

Hospitalization Costs Due To Healthcare Associated Infections An Analysis Of Propensity Score Matching Sciencedirect

International Braz J Urol
Https Uk Sagepub Com Sites Default Files Upm Assets 78123 Book Item 78123 Pdf
Https Aaapubs Org Doi Pdf 10 2308 Accr 51449
Https Scholarworks Umass Edu Cgi Viewcontent Cgi Article 1340 Context Pare

Pdf A Practical Guide For Using Propensity Score Weighting In R Semantic Scholar

Pdf A Primer For Applying Propensity Score Matching Impact Evaluation Guidelines Semantic Scholar

Famotidine Use Is Associated With Improved Clinical Outcomes In Hospitalized Covid 19 Patients A Propensity Score Matched Retrospective Cohort Study Gastroenterology

Full Text Adjusting For Confounding By Indication In Observational Studies A Ca Clep
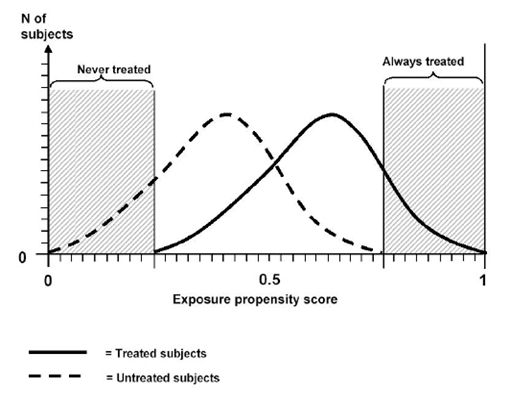
Summary Variables In Observational Research Propensity Scores And Disease Risk Scores Effective Health Care Program

Using The R Matchit Package For Propensity Score Analysis R Bloggers

Pdf An Illustrative Example Of Propensity Score Matching With Education Research

5 Research Methodology Measuring The Effects Of Escc Hr Policies And Maternal Labor Supply

Pdf One To Many Propensity Score Matching In Cohort Studies

Propensity Score Matching Explanation Program Evaluation Scores Evaluation

Pdf Impact Assessment Of Agricultural Research In West Africa An Application Of The Propensity Score Matching Methodology Semantic Scholar
Https Www Stata Com Manuals Teteffectspsmatch Pdf
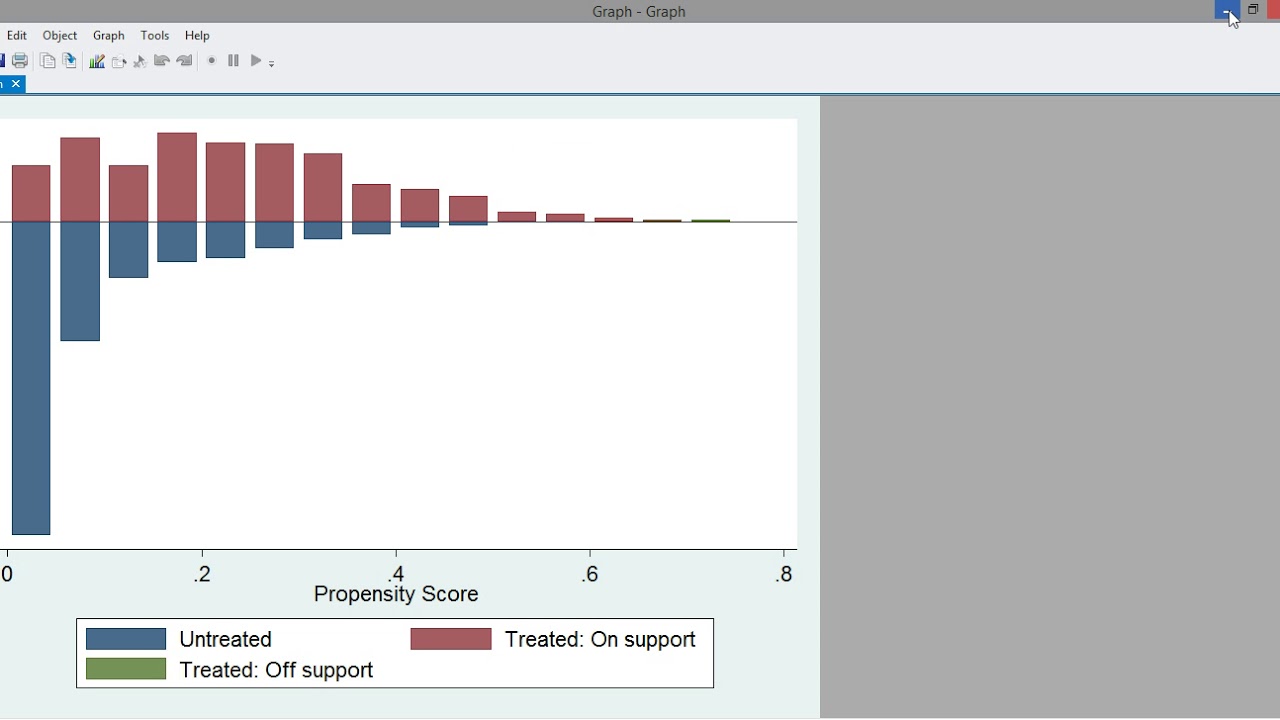
Propensity Score Matching In Stata Psmatch2 Youtube